머신러닝 클러스터링 모델 소개
클러스터링(Clustering)은 데이터를 유사한 특성을 가진 그룹으로 묶는 비지도 학습 기법입니다. 클러스터링은 고객 세분화, 이상 탐지, 이미지 분할 등 다양한 분야에서 활용됩니다. 이번 글에서는 오렌지3를 사용하여 간단한 클러스터링 모델을 구축하고 평가하는 과정을 살펴보겠습니다.
1. 데이터 로드
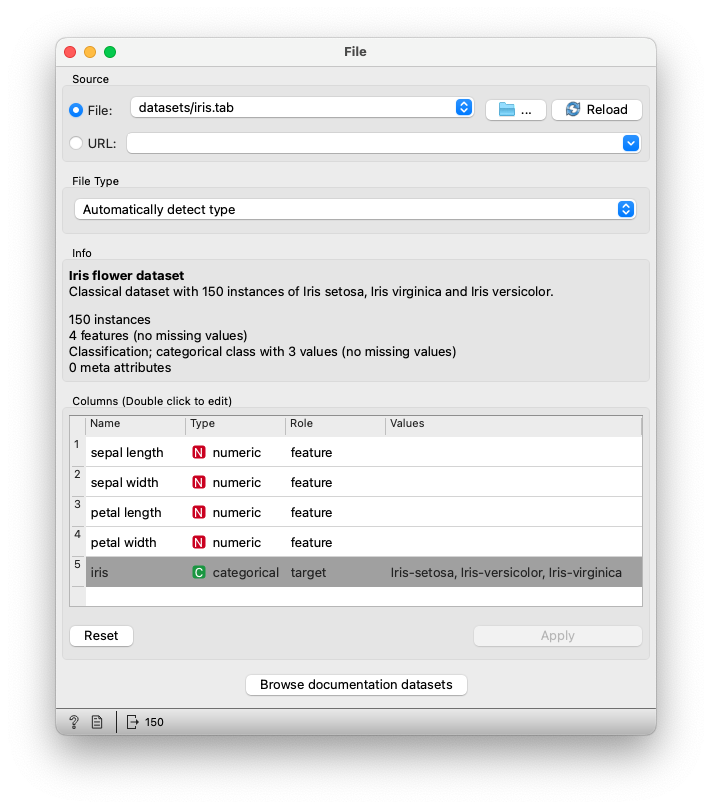
오렌지3를 실행한 후, ‘File’ 위젯을 캔버스로 드래그하여 데이터를 로드합니다. 예제 데이터로 ‘iris.tab’ 파일을 사용합니다. 이 데이터셋은 붓꽃의 세 가지 종류를 포함하고 있으며, 각 종을 클러스터링을 통해 분류해보겠습니다.
2. 데이터 시각화
데이터를 이해하기 위해 ‘Scatter Plot’ 위젯을 사용하여 데이터를 시각화합니다. X축에 ‘petal length’, Y축에 ‘petal width’를 설정하고, 데이터를 시각적으로 탐색합니다. 이를 통해 데이터의 분포를 확인할 수 있습니다.

3. 클러스터링 모델 생성
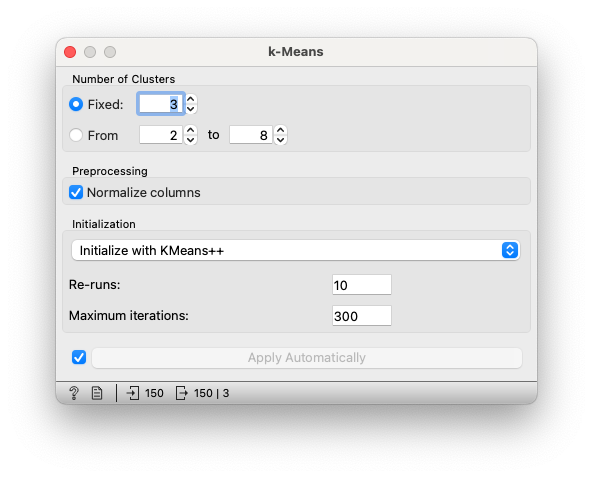
다음으로, 클러스터링 모델을 생성합니다. 여기서는 K-평균(K-Means) 클러스터링 알고리즘을 사용합니다. 'Unsupervised'의 ‘K-Means’ 위젯을 드래그하여 추가하고, ‘File’ 위젯과 연결합니다. 모델 학습을 위해 ‘K-Means’ 위젯을 더블 클릭하여 클러스터 수를 3으로 설정합니다. K-Means는 데이터를 지정된 클러스터 수만큼 그룹으로 나누는 알고리즘입니다.

4. 모델 평가
모델의 성능을 평가하기 위해 ‘Silhouette Plot’ 위젯을 사용합니다. ‘K-Means’ 위젯과 연결하여 각 데이터 포인트가 어느 정도 잘 클러스터링되었는지 평가합니다. 실루엣 계수(Silhouette Coefficient)는 클러스터링의 품질을 나타내며, 값이 1에 가까울수록 좋은 클러스터링을 의미합니다.

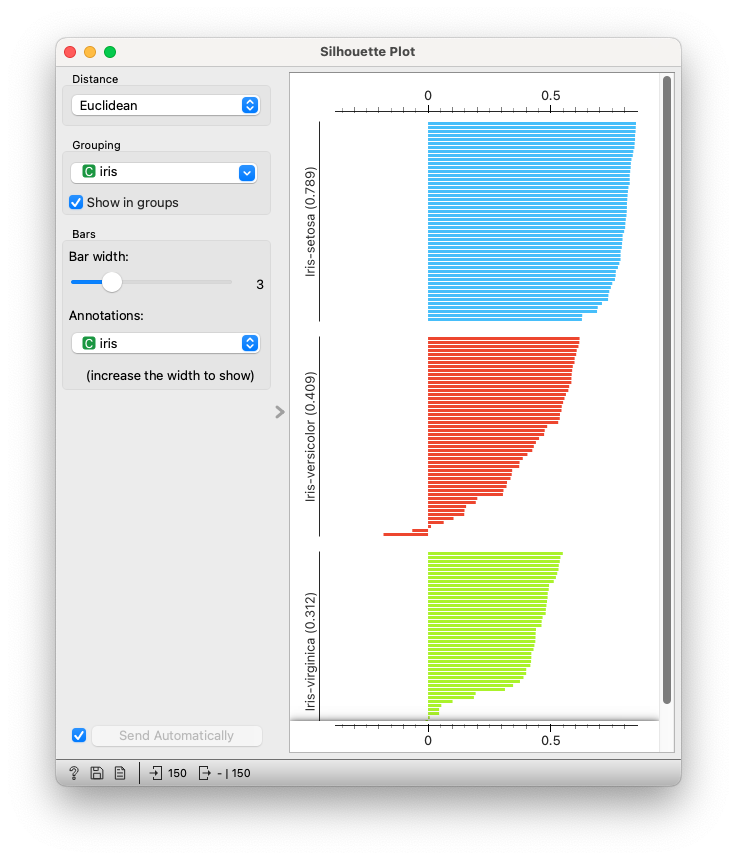
• 실루엣 계수(Silhouette Coefficient): 실루엣 계수는 클러스터링의 품질을 평가하는 지표로, -1에서 1 사이의 값을 가집니다. 값이 1에 가까울수록 클러스터 내의 데이터 포인트가 서로 가깝고, 다른 클러스터와는 멀리 떨어져 있음을 의미합니다.
5. 결과 시각화
모델의 클러스터링 결과를 시각화하기 위해 ‘Scatter Plot’ 위젯을 추가합니다. ‘K-Means’ 위젯과 연결하여 각 클러스터를 색상으로 구분하여 시각화합니다. 이를 통해 클러스터가 어떻게 형성되었는지 확인할 수 있습니다. X축은 ‘petal length’, Y축은 ‘petal width’, 그리고 Color를 'Cluster' 로 설정하여 클러스터가 어떻게 형성되었는지 확인할 수 있습니다.

결론
이번 글에서는 오렌지3를 사용하여 기본적인 클러스터링 모델을 구축하고 평가하는 과정을 살펴보았습니다. 클러스터링 모델은 데이터 분석에서 매우 중요한 역할을 하며, 이를 통해 데이터의 숨겨진 패턴과 구조를 발견할 수 있습니다. 다음 글에서는 다른 클러스터링 알고리즘(예: 계층적 클러스터링, DBSCAN)과 그 활용 방법에 대해 자세히 다루겠습니다.
'공부공부 리뷰' 카테고리의 다른 글
| [머신러닝] 머신러닝 모델: 회귀 모델 (Feat. 오렌지3) (0) | 2024.06.25 |
|---|---|
| [머신러닝] 머신러닝 모델: 분류 기법 (Feat. 오렌지3) (0) | 2024.06.22 |
| [머신러닝] 머신러닝의 종류와 분류(feat. 오렌지3) (0) | 2020.09.13 |
| [Orange3] 오렌지3를 이용한 머신러닝 모델 생성 및 예측! - 새로운 눈을 뜨게 해 준 머신러닝 야학 (0) | 2020.08.24 |
| [머신러닝] 오렌지3(Orange3) - 나에겐 충격적인 GUI 기반의 머신러닝툴 (0) | 2020.08.15 |




